A day doesn’t go by without hearing about AI, ChatGPT, and GenerativeAI. It’s true, these technologies are quickly changing many aspects of our daily lives, particularly in business. While there’s certainly a lot of hype out there, now is the time to determine how you can actually leverage these transformative technologies to enhance your business.
ChatGPT is making it possible for anyone to write document summaries, create marketing content, conduct research, generate recipes, and even write code. But while these are powerful ways to use conversational AI, they don’t truly take advantage of the underlying power of the technology known as a Large Language Model, or LLM for short.
The primary strength of an LLM is its ability to derive meaning from conversation, rather than just spout facts, text, and records. Because today’s LLMs were trained on a massive amount of data from the internet, for instance, their historical knowledge is limited by the training data – ChatGPT’s knowledge ends around September 2021. But these models can generate novel, meaningful content.
What if you want to use an LLM to generate an output on current events, or your own non-public data? For this you need a chatbot with extended functionality, and in many business cases, secure access to private data which needs to stay private.
Another strength of LLMs is the ability to reason and work toward a specific goal through a series of communications referred to as “prompts”. Known as Prompt Engineering, this is the act of providing clear instructions to the LLM, and iterating upon a series of steps to arrive at an outcome. You might liken this to describing a series of steps to a (brilliant) five year old so that they complete a task exactly how you intended.
By combining these and other features of ChatGPT, which was only released late last year, we already are able to create custom Chatbots with excellent capabilities. These can serve a variety of duties and use cases within a business, enhancing productivity, improving customer service, and adding value in a way that was not possible last year.
Did you know there are a variety of LLMs out there other than ChatGPT? Did you know that no single LLM is good at everything?
There is a large and growing ecosystem of LLMs and supportive tools from companies like OpenAI, Hugging Face, Anthropic, Meta, AI21 Labs, StabilityAI, and others. Each of these has its strengths and weaknesses, and solutions often use more than one LLM to arrive at the desired outcome.
If you are ready to begin your AI journey and could benefit from applying these technologies to automate your business, Cloud Brigade wants to hear from you! Contact us to have a discussion with our CEO about your challenges and goals.
Contact Us
"*" indicates required fields
Ever wanted to see how good a computer vision model can get? Wanna make it fun? We did too. So with Pi Day on the way, we thought it a great opporunity to carve ourselves a slice of the computer vision action with our Pidentifier Application: A serverless mobile-friendly app that can tell you what kind of pie you’re about to stuff in your face on Pi Day!
The Dataset
The first thing that I had to do in order to build a machine learning model that can use to successfully classify the types of pie slices was to create a training dataset. In our prior experience using Amazon Rekognition Custom Labels, “What’s In My Fridge”, we learned that the image classification and object detection models under the hood in this microservice can be “fine-tuned”.
What that means is that Amazon has already done the really expensive and time-consuming model-building work for us. This allows us to classify objects that are otherwise very similar to one another and historically have been very challenging for a model to distinguish without excessive amounts of data collation and training time. This technological advancement means we can train a model using several hundred photos as opposed to tens of thousands of photos. Plus, this fine-tuned model training lasts only hours instead of days or weeks.
Individual photos of slices of pie, as you can imagine, are easy to find online, but there is no labeled dataset ready-to-go for fast model training. Thus, I took several hours of dragging and dropping photos of individual slices of pie and saving them to my local machine. If I was to translate this to your business, I might ask for as many old photos, or new photos, as possible for your specific objects that will need later classification, preferably each saved in a single folder with the part number or unique object name as the folder name.
Here we see a portion of the “cherry_pie” data folder
To take care of the labeling of my images, I built my own convolutional neural network in Tensorflow. This created a dataset from my saved files that Tensorflow labeled using the names of the folders where I saved the photos. After successfully getting a Tensorflow model working with my tiny dataset, I moved the files to the cloud.
Amazon S3 allows us to store terabytes of data in a single s3 uri location, making the creation of a photo image dataset pretty easy. All I had to do was to utilize the AWS command line interface, or CLI, and then move the images from my local machine up to the S3 bucket. From there, utilizing either Amazon Sagemaker or Amazon Rekognition is a breeze.
The Models
As mentioned above, we had experience last year using Amazon Rekognition Custom Labels to identify the various products that were in our office fridge. We could distinguish various flavors of sodas by fine-tuning the convolutional neural network models that were pre-trained under the hood. This is known as transfer learning, where you utilize a model that was already trained on data before, and then add your own smaller dataset to it while re-tuning the model’s hyperparameters to suit your needs.
The great thing about Amazon Rekognition Custom Labels is that the microservice does a lot of this work for you. Amazon provides a graphical user interface where we entered the name of our s3 bucket and the folders where our data live, and then with a few clicks, the model fine-tuning begins. It takes a few hours to train the model as we entered in about 1500 photos for training.
Once trained, Amazon Rekognition Custom Labels provides a printout of the model’s evaluation metrics, revealing the Accuracy, Precision, Recall, and F1 scores for each class. In this case, there were 14 classes, or 14 different kinds of pie slices, that the model was trained to classify. Our model correctly identifies each pie with 97% accuracy and 97% F1 score (F1 is the harmonic mean of precision and recall–or in other words, the model’s really really good).
The API
In order for us to put this model into production, it was necessary to create a RESTful API which could serve our model. For this, we also didn’t have too much heavy lifting. Amazon takes care of the inference API for you by providing an ephemeral endpoint server and some code to access the RESTful API for you. From there, I just had to program the API Gateway.
Since we don’t want to expose our AWS account to the world and risk hacking or cyber attacks, we utilized the Amazon API Gateway. API Gateway allows us to write our own RESTful API where anyone on the web can send a request, and then the API gateway activates Lambda functions to either hit the Rekognition API, save data to S3, or return a response to the front-end application without opening the door to our own account.
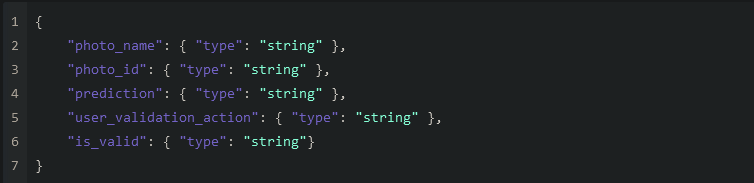
example of a json payload schema for the API Gateway
Programming the API Gateway does take a bit of care and practice. Unlike Rekognition Custom Labels, the API Gateway requires many layers of steps to make sure that the Python and json are written correctly, the api schema is programmed correctly to accept requests and return the correct error messages, and to finally utilize the correct lambda functions depending on the information that is sent to the API from the client side.
The result is that we now have three separate Lambda functions that respond in their own way to different formats of requests sent to them, which will be described further below..
The GUI Application
Finally, in order for a human user to interface with our model, we created a GUI, or graphical user interface (often just called an “app”) using a simple HTML5 application. As the Machine Learning Engineer, I wanted to test out the API with a working prototype before my dev team had put together a front-end app. I built one using the Streamlit library in python.
Streamlit employs some pretty easy pre-made HTML and javascript to produce a front-end application that I can write entirely in python. As a Machine Learning Engineer, this allows me to iterate quickly, to develop my application on my own machine without the need for extra overhead, and it lets me produce the application backend without using the design or development team, saving time and money all around.
The user-app is slightly different from my prototype app. In the live production application, the user triggers the workflow by taking a photograph of a slice of pie with their mobile device or smartphone.
In the prototype app, I add the filename of an out-of-sample photo image to the app to start the workflow. What happens next is simple:
The user takes a photo of the slice of pie
A unique filename is assigned to the photograph
The photograph is saved to s3
The API gateway receives the photograph and inferences it against the Rekognition Custom Labels API
A response is sent to the application with the image classification
That response is also saved to the data store to classify the image
The user is asked to verify if the pidentification was correct
If the user fails to respond, a negative, or “false” response is sent to the data store and the original prediction stays in the data store
Else if the user responds and verifies, their answer is logged and sent to the data store
If the user indicates that our prediction was wrong
then they are asked to tell us what the name of the pie should have been
Their answer is sent to the data store
The user is then given the chance to take a new photo of another slice of pie
Conclusion
In this post I’ve walked you through my process to
Create and label a sample dataset
Train and save a deployable Machine Learning Model using Amazon Rekognition Custom Labels
Build and deploy a RESTful API with Amazon API Gateway and AWS Lambda
Build and deploy a prototype Front-end application to showcase this to our customers
Whether you’re a little nerdish, or a full-silicon-jacket nerd like me, I hope that you’ve enjoyed this read and that you’ll consider the expertise that Cloud Brigade can lend to help your business move into a place of modernization through the embrace of AI.
Matt Paterson, Machine Learning Engineer January 14, 2022
Background
In a blogpost from last summer, “Creating Simplicity in the Workplace with NLP”, I talk about using Natural Language Processing (NLP) to route or dispatch incoming emails to their appropriate recipients. We decided that an interactive demonstration of our SmartDispatch system would be more useful to our customers than an essay alone. This paper will walk you through how I went about building:
A dataset to use for NLP Machine Learning Model Training
A fine-tuned BERT model from the HuggingFace Library
A Deep Learning Neural Network for model training
A PyTorch Model Artifact to use for topic predictions
A PyTorch Model Artifiact to use for sentiment analysis
A RESTful API built in FastAPI to deploy the models
A front-end interface to display this functionality built in Streamlit
A plan for the model to improve over time after deployment
The Failed Dataset
I first wanted to find a good sampling of business emails in order to train the model. Since our clients will be mostly from small and medium sized businesses, where emails are likely to not be tagged for relationships with internal teams or departments, I wasn’t necessarily looking for a labelled dataset.
What are labels?
By “labelled” dataset, I’m referring to a set of emails or text messages that are each labelled with their topic or business department or function. With these two data points for each observation, the message and the label, I can train a model to know what marketing emails look like versus what an IT Helpdesk email looks like. A functioning model would then be able to predict the email or text message’s topic from a list of several options.
But those Emails…
In a cursory search, I quickly found the Enron Email dataset via the Kaggle website. This set of over a half million unlabelled emails became the foundation of our research. However, this proved problematic.
A big problem was that the emails in this corpus were predominantly interpersonal communications between colleagues. Since our end-goal is to create an email interpreter that will surmise the topic, tone or sentiment, and possibly the level of importance of an email as it enters the general inbound queue for a customer service team, we needed to be able to find clear differences in the text that could be coded.
But it’s a computer?
There’s a saying in ML that if a human can do it, then a computer can do it too. While not reflexive in every case, if a human cannot create a delineation between two written messages, then our current NLP capabilities in 2022 cannot do so either (ie., if I can’t understand your text message then Artificial Intelligence can’t do it either). Thus, rather than clear signals to indicate meaning, these interpersonal emails only added noise to our model.
Another big challenge with using this unlabelled dataset was our strategy for labeling it. Obviously, I couldn’t read 500K emails and label each as one of 5 categories by hand, that would take an inordinate amount of time. We thought about bringing on interns from the local University, but we decided that simply reading and labelling emails wasn’t a good use of anyone’s time, student or professional.
The LDA Model
There exist a number of unsupervised learning methods to deal with such a challenge. The NLP solution that is the most popular for this right now is called LDA, which stands for Latent Dirichlet Allocation. LDA is effective at creating clusters within a corpus of text by selecting similarities in the vectorized text, and then grouping text together into like categories.
A Cluster What-Now?
Clustering is a process by which the computer looks at similarities between data observations, in this case emails or text messages, and groups masses of them together in like-clusters. We do a similar thing in bookstores when we put the gardening books in one section and the sci-fi in another, and the poetry in yet another part of the bookstore. You can also think of how kids group up on a playground, or how in a city of a hundred thousand people you’ll find that the different bars each attract their own particular type of person. It’s like that.
Ready-made microservices
AWS has an LDA model at the ready in their microservice called Amazon Comprehend. While I later coded up my own LDA in order to have more autonomy over the fine-tuning of the model, I started off by asking the Comprehend application to label our 500K emails first into 3 subjects and then into 5. I actually repeated this step a few times as each individual pass of the clustering model can result in slightly different groupings of the text.
The Data Scientist can choose the number of clusters, but to actually interpret and label them, it often takes a solid and focused human eye to read tens of emails in order to interpret how the model had clustered the texts. In one trial I clearly discerned a “Regulatory” category, a “Sales” category, a “Meetings/Travel” category, and a separate “Legal” category, leaving all else labelled “Interpersonal”. As sure as I thought I was here, there is no guarantee that your first or second or twelfth attempt will result in a reliably labelled dataset.
Death by Confirmation Bias
Often in our trials when it appeared that we were successful in labeling the emails with this approach, we would find after a day’s rest that our best clusters were a result of chance and confirmation bias in the sub-sample that I reviewed, and further the conclusions that I made didn’t necessarily map to the whole cluster.
To put it another way, I had seen the face of Keanu Reeves on the side of a building in San Francisco and thought that I’d discovered the Matrix (the movie not the nightclub). There were no clear labels for these clusters, I was only willing them to appear in front of me. Just as our eyes and our minds can play tricks on us (there is no spoon), our efforts to be good scientists can rival our human need to be successful creators (if my mixed metaphors were too much, there were no clear labels for the clusters in my trials after all).
Alternative Dataset
Given this realization, the second phase of our process involved shifting gears. This is where I found our winning dataset using the python Requests library to create a labeled dataset though an API to access social media posts.
Leaning on Past Experience
One of my prior projects in NLP involved using a free public API to pull posts and comments from social media sites in order to build a labelled dataset. Since I had this experience already, I went ahead and built a program that would hit the API and pull down about 80K posts and comments from 16 different labelled threads. I then labelled each with one of five topics, depending on which thread the message came from: “MachineLearning”, “FrontEnd”, “BackEnd”, “Marketing”, or “Finance”.
Good Data In -> Good Predictions Out
This proved to make a much more accurate predictor in the end. Essentially, we want to use natural, conversational language to train a model on the sequences of words that tend to be members of each of the aforementioned classes. For example, the goal is to train it to “know” the difference between the following:
{ ‘label‘ : ‘MachineLearning’,
‘Message’ : ‘We’re building a model in PyTorch to predict the topic of emails’}
VERSUS
{ ‘label‘ : ‘Marketing’,
‘Message’ : ‘We’re building our emails with drawings modeled on the Olympic Torch’}
Both of these messages contain the keywords “We’re”, “building”, “model”, “emails”, and “Torch”, yet each is clearly part of a different silo of the business.
To achieve our goal, we didn’t necessarily need to start with actual emails as our dataset. Instead, I could build a labelled dataset of key topics using an already-labelled source of natural, conversational language. Since the social media threads were already labelled with words such as “reactjs” or “javascript” or “webdev”, I could then put several of these together, in this case given the label of “FrontEnd”.
The NLP Transformer Model using Deep Learning
Finally, I took the 80K labelled entries, known as “documents” in the parlance of NLP, and used them to fine-tune a pre-trained Transformer model known as BERT. I did this thanks to the HuggingFace Library of models and algorithms (https://huggingface.co/models).
While our model is 80% accurate with 80% average precision at predicting each of the 5 topics, I could greatly improve the accuracy of this model by scraping more data, evening out the sample imbalance, and adjusting other hyperparameters in our training job.
We built our 5-class Classification Model by utilizing a process in Machine Learning known as Transfer Learning to fine-tune a pre-trained model. In our case, we utilized BERT, a model that Google pre-trained on over 3 Billion words from a couple of sources including Wikipedia to learn word embeddings and relationships through Bi-Directional Encoding using Transformers. (BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2019, Devin, Chang, Lee, Toutanova, https://arxiv.org/pdf/1810.04805v2.pdf)
With the help of the Huggingface Transformers Library, we built out a custom library in PyTorch that I named Hermes after the Messenger of the Gods. As mentioned above, we began work with an LDA model in order to create labels for data that was previously unlabelled, and tried to apply this newly-labelled dataset first. This proved problematic for Hermes as the results were never better than a 42% accuracy, which is barely above a baseline model or null model. To clarify, in data science a baseline model, or null model, is the simple average (mean) of the target variable.
Put more simply, if I have 3 topics, “A”, “B”, and “C”, but my model always predicts that everything I put in will be part of topic “B”, then my model will be correct 33% of the time. If I have 5 topics and predict the same one each time, then my model will have 20% accuracy.
Since the first dataset, the Enron Emails, did not offer enough differences in their embeddings to fine-tune a pre-trained model with any reliable accuracy, we turned to our alternative dataset, the social media posts and comments described above.
Using my HermesDataset object, a custom built PyTorch Dataset (if you’re geeky, this inherits from torch.datasets.Dataset) and the HermesPredictor library, I was able to create a custom PyTorch model artifact that predicted with reliable accuracy.
There are many like it but this one is mine
My model, called HermesModel_80.pt, can ingest a vectorized message and predict that message’s topic from the 5 options with 80% accuracy and 80% average precision. I know, it’s pretty cool, right? After training the model on a GPU instance through a Deep-Learning optimized Amazon SageMaker Notebook Instance (p3.xlarge), I saved my model artifact to an S3 bucket so that I could access it later on a much smaller instance kernel and use it for inference.
While a fully-functioning and deployed model inside of a customer’s email queue could be trained to well above 90% accuracy using a larger training set, more hyperparameter tuning, and better control for pre-training sample imbalance, I’m very happy with the resulting application. I also used a sentiment analysis dataset that I have used in prior scholastic work, and I ran that dataset through the HermesPredictor library in the same manner to create a 90% accurate sentiment analysis model called HermesSentiment_90.pt.
Amazon Built-in Options
Amazon recently has created its own wrapper to fine-tune pretrained Transformer models using the Huggingface Transformers and other libraries. You can now use the SageMaker SDK, or utilize Amazon Sagemaker console, to deploy a pre-trained BERT model from the Huggingface library onto your dataset.
Unfortunately for me, in the short time I had to work on this project I did not find a good resource for building a data pipeline from raw text to a pytorch Dataset object that could be fed into the dataloader in a format readable by the BERT model. Thus, I chose to use native PyTorch outside of the sagemaker SDK this time, though I still called on Amazon’s SageMaker Notebook instances to utilize the CUDA GPU’s required by PyTorch.
The API
In order for us to put this model into production, it was necessary to create a RESTful API which could serve our model. According to wikipedia, “The REST architectural style emphasizes the scalability of interactions between components, … to facilitate caching components to reduce user-perceived latency, enforce security, and encapsulate legacy systems”. Thus it allows us to run inference on our model in the cloud and frees up processing time and reduces latency on the client side.
Jumpin Jack FastAPI
For this purpose I chose to use FastAPI as it is a 100% python solution. A lot of documentation around RESTful API’s on the internet are written with node.js or JavaScript programmers in mind, and for good reason–JavaScript is the ubiquitous language of our modern internet. However, as a Machine Learning Engineer who knows very little about utilizing the Document Object Model (that’s what our Front-End Devs are good at!), I appreciate a framework that allows me to build the API in a very short time so that my model can be utilized faster in a production capacity. Think of a much faster time to POC, and you can bring in the paid web devs if the model is promoted to MVP.
Why So Fast?
FastAPI is also fairly lightweight and can run locally or in the cloud, serving inference from both models with minimal latency. We would increase the response speed of our downstream application by creating separate API’s for each model, possibly even creating a third API to handle the text encoding, and then running them from separate servers or separate virtual machines in kubernetes or docker containers, but our goal for this exercise is to create a demonstration application so for now, a two or three second lag-time requires no further re-tooling.
Also, the majority of our use-cases for this tech will occur under-the-hood of one of our customer’s enterprise email systems, although through putting our model into a FastAPI architecture, we could repurpose the model to work in chatbots, document review systems, or even internal help queues that review documentation for easy solutions.
The GUI Application
Finally, to give us humans a way to work with our API, I created a front-end application, or what is called a Graphical User Interface (GUI) using the Streamlit library in python. Streamlit employs some pretty easy pre-made HTML and Javascript to produce a front-end application that I can write entirely in python. As the developer, I only need to know the Python to use Streamlit.
As a Machine Learning Engineer, this allows me to iterate quickly, to develop my application on my own machine without the need for extra overhead, and it lets me produce this application without taxing the design or development team. Once a client asks us to build them a custom solution, the front-end team can then go to work to marry my API and Data Science Model to the customer’s color schemes, look-and-feel, and embed that naturally into existing software for their users if they want a customer-facing interface.
My Streamlit application can also be served from the same server or virtual machine that I serve the API from, however doing so can add latency since the server can only do one thing at a time–running code for the front-end app, the API, and inference against the endpoint sequentially.
A lifetime-learner
In our current era, we expect all new AI to be more sentient than it actually is. As such, we expect that any new inference device like SmartDispatch will improve over time. We see this in our smartphones as the voice assistant application will start to recognize our accent or dialect and make better recommendations the more we talk to it.
To add this functionality to the SmatDispatch App, there are several strategies that we can employ. One would be adding each incoming message as a new labeled data point and fine-tuning our model periodically over time. For this we would also use a feedback loop from human users that review the emails (known as “Human-In-The-Loop”). A second strategy would include pulling more labelled social media posts over time to pick up conversations about new technology or evolving nomenclature in each of the topic classes.
The final strategy would be a combination of these and and steps in what is called an ensemble model. We would create an algorithm that couples this ensemble with a heuristic that measures the accuracy, recall, and precision metrics of the subsequent models and chooses the champion model to automatically deploy back into the app. Of course, just as human beings need an annual checkup by a physician, a production model requires regular model maintenance to detect and handle model drift by a Data Scientist, and Cloud Brigade can be there for this regular checkup.
Conclusion
In this paper I’ve walked you through my process to
Create and label a sample dataset
Train and save a deployable Machine Learning Model artifact in PyTorch
Build and deploy a RESTful API in FastAPI to serve the model
Build and deploy a Front-end application to showcase this to our customers
Whether you’re a little nerdish, or a full-silicon-jacket nerd like me, I hope that you’ve enjoyed this read and that you’ll consider the expertise that Cloud Brigade can lend to help your business use AI to modernize and stay ahead of the competition.
If you like what you read here, the Cloud Brigade team offers expert Machine Learning as well as Big Data services to help your organization with its insights. We look forward to hearing from you.
Please reach out to us using our Contact Form with any questions.
If you would like to follow our work, please sign up for our newsletter.
Expansive website needed to be migrated and then optimized for user experience and search.
Benefits
Website now supports e-commerce
Web search rankings remain high
User experience is optimized
IT systems are fully supported with quick response
Summary
Customer Since 2005
Located in Scotts Valley, CA
Industry: Industrial Supplies and Manufacturing
Company Size: Midsize Enterprise
Garrett Gettleman, President and CEO
Founded in 1996, Nationwide business
Business Challenges Solved
Skills and Staffing Gaps – The small staffis focused on product sales and manufacturing. not IT matters
Inefficient Systems and Processes – Web content needs to be pushed out to a content delivery network to ensure content loads quickly and page rankings stay high
Irresolvable Complexity – SEO properties of web content must be carried over from an old website to a new one without loss of search rankings
About Solar Electric Supply
In business since 1996, today Solar Electric Supply is one of the nation’s largest wholesale suppliers of solar panels, solar power systems and components. The company manufactures pole and pad mounted solar systems for remote outdoor applications and provides complete solar electric systems for Home, Business, Commercial, Government and Remote Industrial Applications.
Background
The small staff at Solar Electric Supply is focused on servicing the solar energy needs of customers across the spectrum. The website is a force multiplier, allowing the company to reach the largest possible audience throughout the country. Cloud Brigade optimizes the site for search and provides ongoing support and maintenance to keep performance at its best.
Why Cloud Brigade
Solar Electric Supply President and CEO Garrett Gettleman has known Chris Miller, Founder and CEO of Cloud Brigade, since their high school days. When Gettleman needs anything related to IT, he turns to his old friend Miller. “He covers all the bases and has my back,” he says. “Typically, I wouldn’t do anything or make any move unless I was using Cloud Brigade because of the relationship I’ve had for many years.”
“Cloud Brigade has the ability to look at a very big and complex problem, quickly identify what’s required, and also identify things that might not be initially apparent but which also need to be responded to. And then they dig in and resolve the problem.”
– Garrett Gettleman, President and CEO, Solar Electric Supply
The Importance of SEO for Driving Increased Revenue
Solar Electric Supply sells many thousands of products, components, and complete systems via its website. The online catalog gives the company a nationwide reach. Gettleman has always been savvy about the power of search engine optimization, or SEO, to draw more visitors to the website. This is the notion that the site can be optimized to increase its visibility for relevant searches. The better visibility that pages have in search results such as those shown by Google or Bing, the more the company is able to attract customers to the business.
Many companies don’t even realize the importance of SEO and thus don’t have it built into their websites. This is a lost opportunity to garner more eyeballs on the website and, more importantly, more interest in the business and sales in the shopping cart. Having high visibility and ranking in search results can have a significant material impact on a company’s revenue.
Optimizing SEO Was No Easy Task
When Solar Electric Supply needed a new website based on more advanced technology, the site was created in stages. “We had an expansive website with more than 1800 pages. The content is very rich,” says Gettleman. “Unfortunately, that site didn’t support a key technology that is important to our business. We decided to move to version 2.0 of a platform called Magento so we hired someone to do the data transfer.
He’s a script programmer and his sole task was to migrate the content from the old to the new platform.”
Once the data was migrated, Cloud Brigade was brought in to do the heavy lifting of the SEO process. With so many web pages and so much content, this was an enormous task because it involved remapping the URL page-naming structure from the old site to the new one without losing the carefully cultivated existing SEO rankings. It’s a pain-staking process, so Cloud Brigade developed internal tools that enabled a comparative audit between the old and the new websites. The tool is able to find where pages, content, or the URL changed that will result in a drop-off in SEO rankings. Thus, Cloud Brigade is able to address those issues to preserve a high degree of SEO placement.
“When the new website was handed over to us, we did an audit to determine the current state and what needed to be fixed in terms of SEO,” says Chris Miller of Cloud Brigade. “Initially there were more than 10,000 SEO-related errors that needed to be fixed on the site. For some of those things, there was a coding issue. We fixed a piece of code and that resolved the issues with a bunch of URLs. For many others, we had to go over them manually. We did everything we could to minimize any kind of negative search engine impact that would occur as a result of launching the new website.”
Customizing the Website for a Great User Experience
Cloud Brigade optimized the website in other ways as well. One was to set up the Amazon CloudFront content delivery network (CDN) in order to serve up content very quickly no matter where a user browsing the site is located. A CDN makes a copy of the assets of a website that are typically slow to load – for example, images and style sheets – and distributes those assets to cloud-based servers around the world. Thus, a person who is browsing the website from halfway around the world from where the website is hosted still gets a good experience in loading the content for viewing because there is less latency in presenting web pages.
Using a CDN to expedite content delivery is an important factor in SEO rankings. Google and other search engines incorporate how performant a website is into their search rankings by calculating a Core Web Vitals score. So, for instance, a website that has pages that are slow to load may rank lower in searches than websites with fast-loading pages. A CDN helps eliminate that problem so that search rankings aren’t negatively affected by page performance.
“Cloud Brigade hosts Solar Electric Supply’s website on Amazon Web Services (AWS), so we set up a CDN profile inside of AWS. We tell CloudFront where to find the origins of the files from the website, which are in a Magento content management system. We customized Magento to reference the CDN for all the links to the image files, JavaScript, and so on,” says Miller.
Cloud Brigade Provides Good Value
“There aren’t a lot of companies that have the skills and tenacity for problem-solving that Cloud Brigade has. They provide a lot of value in what they do,” says Gettleman. ” I’ve worked with many other developers and IT support professionals over the years. Typically they just run the meter. It’s not that way with Cloud Brigade. They go out of their way to try to optimize whatever they do to bring you value. They don’t work on things that they know are a waste of time, and they really are efficient with their time.”
Gettleman stresses how his company benefits from Cloud Brigade’s ability to do so much under one umbrella. “In most cases, I would have to hire two or three different companies to get what Cloud Brigade provides us. We’d need one company to develop the website from the programming and Magento perspective, and another to tackle any specific programming or form needs that are outside the Magento scope. And then a third company would be needed to understand and optimize SEO because that is a real niche. Cloud Brigade does it all under one roof and that’s really unique today. It truly saves us quite a bit of time and money.”
“I highly recommend other companies look at Cloud Brigade for developing any new project or taking over their current IT needs or projects. Chris Miller’s team is very knowledgeable, responsive, and professional as well as competitively priced.”
– Garrett Gettleman, President and CEO, Solar Electric Supply
Technology
Software: Magneto, Joomia
Programming Language: JavaScript, PHP
Cloud Infrastructure: AWS, (EC2, CloudFront, RDS)
Services
Application Migration, Support and Maintenance- Supported the migration of the website to a new e-commerce platform and re-established critical SEO links
Cloud Infrastructure Support – Host the website and set up a content delivery network to ensure content loads quickly and page rankings stay high
Strategic IT Support– Ongoing advisor on all matter pertaining to IT
If you like what you read here, the Cloud Brigade team offers expert Machine Learning as well as Big Data services to help your organization with its insights. We look forward to hearing from you.
Please reach out to us using our Contact Form with any questions.
If you would like to follow our work, please sign up for our newsletter.
The Amazon Heroes program was established to recognize innovators who have gone above and beyond in providing valuable information and unique perspectives in the Tech and AWS community. AWS Heroes are recognized all around the globe and being deemed one is a distinctive honor. Heroes clearly convey the new discoveries they have via blog posts, social media, etc.
Very recently, CEO of Cloud Brigade Chris Miller was named as one of the six AWS Machine Learning Heroes in North America (31 Globally). Chris has devoted himself to his passion of constantly finding new ways to implement AI and ML technology into everyday scenarios to make our lives simpler.
In recent years he has embarked on a variety of AI projects including the AWS DeepRacer Open Source project. DeepRacer is a 1:18th scale self-driving model car, and was designed to introduce the capabilities of ML technology in a fun way to software developers.
Chris was tasked by AWS to expand on capabilities of the DeepRacer by implementing AI technology that allowed the autonomous car to control a toy blaster. This fun yet ingenious innovation, and the knowledge sharing is the type of work Chris enjoys working on and hence the reason he was deemed an AWS Hero.
Chris is honored to be in such a prestigious group of individuals and looks forward to sharing his ideas and discovery with the community.
If you like what you read here, the Cloud Brigade team offers expert Machine Learning as well as Big Data services to help your organization with its insights. We look forward to hearing from you.
Please reach out to us using our Contact Form with any questions.
If you would like to follow our work, please signup for our newsletter.
A day doesn’t go by without hearing about AI, ChatGPT, and GenerativeAI. It’s true, these technologies are quickly changing many aspects of our daily lives, particularly in business. While there’s certainly a lot of hype out there, now is the time to determine how you can actually leverage these transformative technologies to enhance your business.
It’s PI DAY!!! Can you stump our Pidentifier? To demonstrate rapid prototyping with AWS Rekognition, and also for fun, we built a serverless mobile-friendly app for Pi Day. It’s impressive how accurate the computer vision model is with a relatively small dataset. This just highlights the advancements in object classification and opens the doors to so many use cases.
Matt Paterson, Machine Learning EngineerJanuary 14, 2022 Background In a blogpost from last summer, “Creating Simplicity in the Workplace with NLP”, I talk about using Natural Language Processing (NLP) to route or dispatch incoming emails to their appropriate recipients. We decided that an interactive demonstration of our SmartDispatch system would be more useful to our
https://www.solarelectricsupply.com/ Challenge Expansive website needed to be migrated and then optimized for user experience and search. Benefits Website now supports e-commerce Web search rankings remain high User experience is optimized IT systems are fully supported with quick response Summary Customer Since 2005 Located in Scotts Valley, CA Industry: Industrial Supplies and Manufacturing Company Size: Midsize
The Amazon Heroes program was established to recognize innovators who have gone above and beyond in providing valuable information and unique perspectives in the Tech and AWS community. AWS Heroes are recognized all around the globe and being deemed one is a distinctive honor. Heroes clearly convey the new discoveries they have via blog posts,
Cloud Brigade is setting out to answer the question: Can AI and Machine Learning help uncover actionable insights on the health and direction of your business using the data that you already own?
Challenge: Can Machine Learning help your Marketing Strategy by implementing better Segmentation Models? Are you using all of your data wisely? How deep is your data lake, and can you even handle all of it? What if there were a way to use all of your customer data to find the customer segments with the
Wouldn’t it be great if you had an automated assistant, capable of acting as your first point of contact with your clients, and intelligently escalate communication with the right person? That’s just one use of Natural Language Processing, or NLP.
Challenge: Have you ever started an exercise program or a diet only to be deterred by a couple of happy hours and a Taco Tuesday Too-Many? I have. Have you ever gotten a funny suggestion from your doctor after an annual physical about what you are eating or how often you stand up and sit
Challenge: Farmers all over America are experiencing a worker shortage amidst the global pandemic, and as labor costs rise per worker, the need to have an automated solution to visual crop monitoring has never been greater. In a small family business, it can be very expensive and tedious to walk or drive every acre to