by Kate Miller | on | in Amazon Glacier, Amazon S3, APN Technology Partners, Storage
This is a guest post by Kelly Boeckman. Kelly is a Partner Manager at AWS who is focused on the Storage segment.
Benjamin Franklin once famously said, “In this world nothing can be said to be certain, except death and taxes.” It’s worth noting, however, that Ben was living in the late 1700s, and was unable to conceive of a third certainty: data growth.
Data deduplication is a critical solution for runaway data growth, as it can reduce the amount of data that needs to be stored or backed up. It also shortens backup windows, dramatically lowers infrastructure costs, and enables cost– and space-efficient data clones for testing, QA, etc. This unlocks a door to the Shangri-La of “Do-More-With-Less.”
So you’ve got your data safely deduped and stored in Amazon Simple Storage Service (Amazon S3), but surely that data can provide more value than just sitting there? Other teams across your organization could undoubtedly derive value from copies of that data. Maybe your developers could create new features or QA teams could more accurately test against your code base if they can test against a whole set of your cloud data.
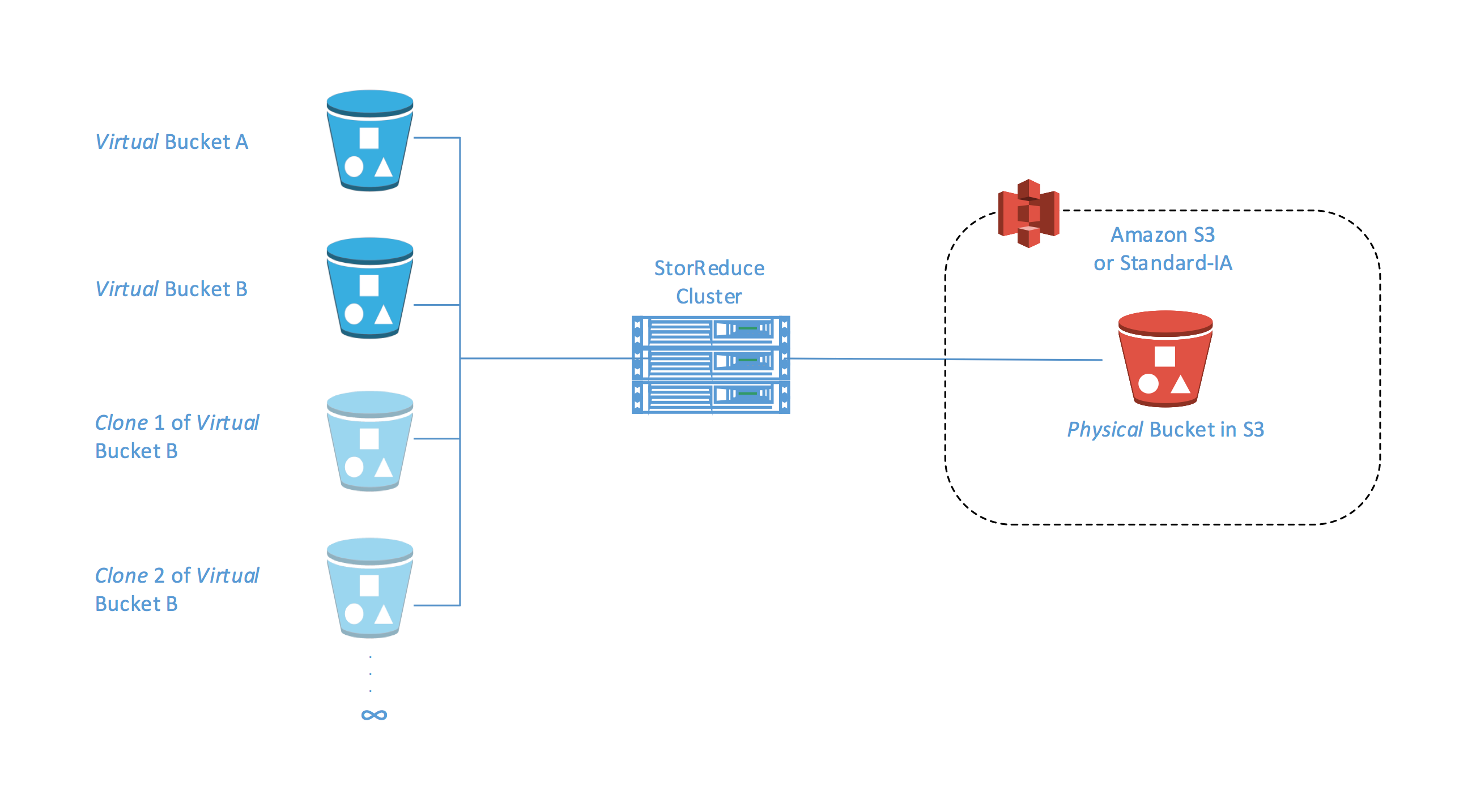
Today, we want to tell you about an innovative solution in this space from APN Technology Partner StorReduce that can help you do more with your data for less. StorReduce has announced support for cloning on object storage such as S3 and Standard-Infrequent Access (Standard – IA). This support allows users and administrators to make copy-on-write copies of objects stored with StorReduce in a rapid, space-efficient manner at petabyte scale.
Who is StorReduce?
StorReduce can help enterprises storing unstructured data to S3 or Amazon Glacier on AWS to reduce the amount and cost of storage significantly. It also offers enterprises another way to migrate backup appliance data and large tape archives to AWS.
StorReduce’s scale-out deduplication software runs on the cloud or in a data center and scales to petabytes of data. The variable block length deduplication removes any redundant blocks of data before it is stored so that only one copy of each block is stored. StorReduce provides throughput of more than 1 gigabyte per second per server for both reads and writes. A StorReduce cluster can scale to tens or hundreds of servers and provide throughputs of 10s to 100s of gigabytes per second. StorReduce is suitable to deduplicate most data workloads, particularly backup, archive, Hadoop cluster backups, and general unstructured file data. Because StorReduce has read-only endpoints and a cloud-native interface, data that it migrates to the AWS Cloud can be reused with cloud services.
Object storage cloning
Storage volume cloning is a long-standing feature of most on-premises NAS and SAN devices—a well-known example is NetApp FlexClone. In these environments, cloning enables fast snapshots of data, creating many additional copies of the data. Depending on the data change rate, deduplication can dramatically reduce the footprint of those extra copies, freeing up storage resources.
StorReduce’s Object Clone brings this feature to S3 and Standard – IA. Leveraging deduplication, a clone can be created simply by copying the references to the unique blocks that have been stored with StorReduce, while leaving the data stored in S3 unchanged.
Copying large amounts of object data may take hours per copy, and – lacking data reduction – you pay for every additional copy, regardless of how much of it is unique.
With StorReduce Object Clone, you need only copy a small amount of metadata. Copying petabyte-scale buckets becomes nearly instantaneous, and multiple clones can be created in rapid succession. Additionally, secondary and subsequent copies of the data are low cost, even at petabyte scale.
How StorReduce Object Clone works
Using the StorReduce dashboard to perform a “Clone Bucket” request is as easy as creating a bucket in StorReduce or S3. Simply navigate to the source bucket to clone. Choose Clone Bucket from the Actions dropdown and specify the target bucket name and StorReduce handles the rest. It creates a duplicate bucket that is owned by the initiator of the request, and which inherits the source bucket’s data.
Clones can also be created programmatically with two API calls, and you can always trace the name of the source bucket. If the source is deleted, this does not affect the operation, the contents of the clone, or access to it.
Benefits
StorReduce Object Clone provides a variety of benefits, including:
- Increased flexibility – Provide cloud-based object storage with the same level of protection available to on-premises files or block data
- Clone entire datasets at petabyte scale as many times as needed, quickly and affordably
- Enable efficient, isolated application development and testing plus research and development against full datasets
- Simplify the cloning of data in object stores, regardless of data deduplication ratios
- Reduced management complexity – Administrators can quickly provide clones and reduce human error
- Subsets of data can be made easily administrable for unbiased application testing
- Protect against human error or malicious deletion of data in object stores
- Make time-based clones of entire buckets and assign read-only access for “locking in” protected data at critical points in time
- Reduced expense – Space-efficient clones consume less space and require less infrastructure
- Enables you to meet your compliance requirements quickly where R&D or development activities require separate pools of data
- Clone only small amounts of data in index or metadata, which reduces the clone size
- Smaller clone size reduces cost of required infrastructure to store data for the second and subsequent copies, even at petabyte scale
Use cases
StorReduce Object Clone provides anyone who is working with a large dataset in S3 (whether that data deduplicates or not) the ability to try experiments and to fail and iterate quickly. Common use cases include:
- Big data, Internet of Things, research – Clone petabyte-scale datasets so that researchers can work independently of each other in their own scratch areas.
- IT operations – Test new versions of software against your dataset in isolation.
- Developers, software testers – Clone your test datasets so that developers and testers can work with the whole dataset in insolation, not just a small subset. Roll the state back after failures and retest rapidly.
- Software quality assurance – Take a lightweight clone of an entire system at the point that it fails a test and hand it back to the developer.
- Hadoop, big data – Take point-in-time snapshots of the state of your cluster and roll back after problems.
To learn more about how AWS can help with your storage and backup needs, see the Storage and Backup details page.
Learn more about StorReduce Object Clone here. To request a StorReduce Object Clone free trial, contact brian@cloudbrigade.com or call (831) 332 1559
This blog is not an endorsement of a third-party solution. It is intended for informational purposes.
What’s Next
If you like what you read here, the Cloud Brigade team offers expert Machine Learning as well as Big Data services to help your organization with its insights. We look forward to hearing from you.
Please reach out to us using our Contact Form with any questions.
If you would like to follow our work, please signup for our newsletter.