In recognition of National Apprenticeship Week, and to celebrate our recently developed apprenticeship opportunity, Cloud Brigade will be hosting the Central Coast Apprenticeship Summit on Wednesday, November 15th, 2017.
Cloud Brigade, in collaboration with Cabrillo College and the Federal Department of Labor, recently developed the first of it’s kind Linux Support Specialist Apprenticeship. It is apprenticeships such as these that can help fill skills shortages, as well as create opportunities for members of our local community.
The Apprenticeship Summit will feature a presentation detailing how local agencies are working to create pathways into the tech industry, and how apprenticeships are an important step in helping to close the skills gap between public education and job requirements. The differences between Bootcamps, Internships, and Apprenticeships will also be discussed, as well how you can participate as part of this long-term solution.
Following the presentation there will be a Q&A session with members of Cabrillo College and Cloud Brigade, and an opportunity to network with other like-minded individuals. A light breakfast and morning beverages will be served.
If you like what you read here, the Cloud Brigade team offers expert Machine Learning as well as Big Data services to help your organization with its insights. We look forward to hearing from you.
Please reach out to us using our Contact Form with any questions.
If you would like to follow our work, please signup for our newsletter.
A new ZDNet/TechRepublic special report dives into a decision many companies are now facing: what to move to the cloud and what (if anything) to keep in the data center.
ZDNet’s Charles McLellan kicks off this feature by taking a look at key trends in cloud and data center usage from the past year. TechRepublic’s Conner Forrest considers whether IT’s default setting has switched from data center to cloud, and he also explains the pros and cons of five different cloud types.
This ebook is useful to all tech leaders, whether they’re going all cloud, sticking to on-premise or going with a little of both. A research report from ZDNet’s sister site, Tech Pro Research, concludes that the majority of companies are using the hybrid approach and goes into detail about what’s moving to the cloud and what’s staying in the data center.
Acknowledging that not all companies will embrace an all-cloud strategy, Mary Shacklett investigates the main reasons to hang on to the data center. For those making the shift to the cloud, Alison DeNisco writes about five major pitfalls to avoid during a migration. Finally, Danny Palmer talked to Fitness First, a gym and health club operator based in the UK, about how a hybrid cloud approach helped the company save money and become more flexible.
If you like what you read here, the Cloud Brigade team offers expert Machine Learning as well as Big Data services to help your organization with its insights. We look forward to hearing from you.
Please reach out to us using our Contact Form with any questions.
If you would like to follow our work, please signup for our newsletter.
IT project requiring an assessment of present and predicted costs and savings falls into two categories: Capex and Opex.
IT operating cost assessments are a vital part of proposing a cloud migration. IT must demonstrate both the department’s and the cloud’s business value. It’s time to baseline and estimate IT operating costs.
Capital expenditure (CapEx) is a nice, solid number that anyone can get their head around. An IT platform, bought via CapEx, is the sum of the amounts paid for the necessary servers, storage and network equipment. Based on a defined renewal period, the hardware is replaced periodically — with that Capex cost planned into the IT budget. Nice and simple.
But, things start to get less solid for a running platform. This involves operational expenditure (OpEx): the total cost of operating that platform.
Few organizations plan IT operating costs well. They know, and plan for, rolling maintenance costs to the hardware, as this is part of the original purchase contract. Determining the costs of the human resources involved in operating the platform requires access to data on the full time equivalent costs of each person on the IT team, which may not be simple for an IT manager to acquire. Additionally, many variables are not under one team’s control: Data center, power, and other utilities maintenance may be under facilities rather than IT. The rise of ‘Bring Your Own Device’ (BYOD) means that much of the cost of providing and managing access devices — such as mobile data costs — are hidden within individuals’ expense accounts.
Many IT teams rely on simplistic chargeback or showback mechanisms, rather than trying to calculate real IT operating costs. Without massive effort and expenditure on controls, monitoring and measurement, it is impossible for an organization to fully understand the costs of running IT. With IT often seen as a cost center, it’s unwise to spend more just to demonstrate how true it really is another means of ascertaining the overall value of IT to the business uses a total value proposition approach, calculating whether a system has an overall positive or negative effect on a business.
Reviews require a solid baseline of existing IT capital and operating costs. Without a baseline, organizations cannot calculate the benefits of a cloud migration.
Many public clouds charge on a predictable recurring basis: per user per month, tiered number of transactions per month or similar structures. It is therefore reasonably easy to calculate future cloud-based hosting Opex costs — but the present state still needs a number.
Assume that users will access the future state platform similarly to how they access the present state. Therefore, discard the hidden variable cost of BYOD. Unless the move to the public cloud results in data center closure, then the existing facility costs will remain — although power costs will drop to some extent.
Still, at best, cloud migration planning is comparing a best efforts guess on the IT operating costs of the present state against the more predictable cloud ops costs of the future state. In itself, this is not a bad thing: The business gains better visibility of the actual IT costs — provided the IT team has good visibility at a granular level of usage and costs from the chosen cloud provider.
This is not just a case of switching to a clear monthly bill for the IT platform, nor is it a case of having a list of IT operating costs broken down by usage types, for example by server, storage and network resource. A flexible, real-time cloud management portal should enable the IT department to define how data is presented to them — by virtual machine or container, by role, by individual user.
With this level of granularity, the IT shop can offer effective and real chargeback or showback to the lines of business — which use this data to make informed decisions.
For example, Department A gets a report showing that its cloud usage cost the business $1300/month. Is $1300 high or low? The cost can be compared to other departments, or the department can drill down to discover the major users and decide if such usage is warranted. IT can present higher-level reports that benchmark departments against each other for some general IT functions, and identify best practices and promulgate them through the business to drive down costs and optimize performance.
It is probably too late and too difficult to determine the overall costs of an owned IT platform — unless it is a complete replacement system wherein the mechanisms to monitor, measure and allocate the costs are built in from the start.
The transition to public cloud gives IT an opportunity to take bold initiative and provide the business with real data on IT operating costs. When a public cloud provider offers useful expense data, IT can go beyond simplistic Opex reporting, and start to provide real value to the business around how to optimize the platform usage costs.
This is a guest post by Kelly Boeckman. Kelly is a Partner Manager at AWS who is focused on the Storage segment.
Benjamin Franklin once famously said, “In this world nothing can be said to be certain, except death and taxes.” It’s worth noting, however, that Ben was living in the late 1700s, and was unable to conceive of a third certainty: data growth.
Data deduplication is a critical solution for runaway data growth, as it can reduce the amount of data that needs to be stored or backed up. It also shortens backup windows, dramatically lowers infrastructure costs, and enables cost– and space-efficient data clones for testing, QA, etc. This unlocks a door to the Shangri-La of “Do-More-With-Less.”
So you’ve got your data safely deduped and stored in Amazon Simple Storage Service (Amazon S3), but surely that data can provide more value than just sitting there? Other teams across your organization could undoubtedly derive value from copies of that data. Maybe your developers could create new features or QA teams could more accurately test against your code base if they can test against a whole set of your cloud data.
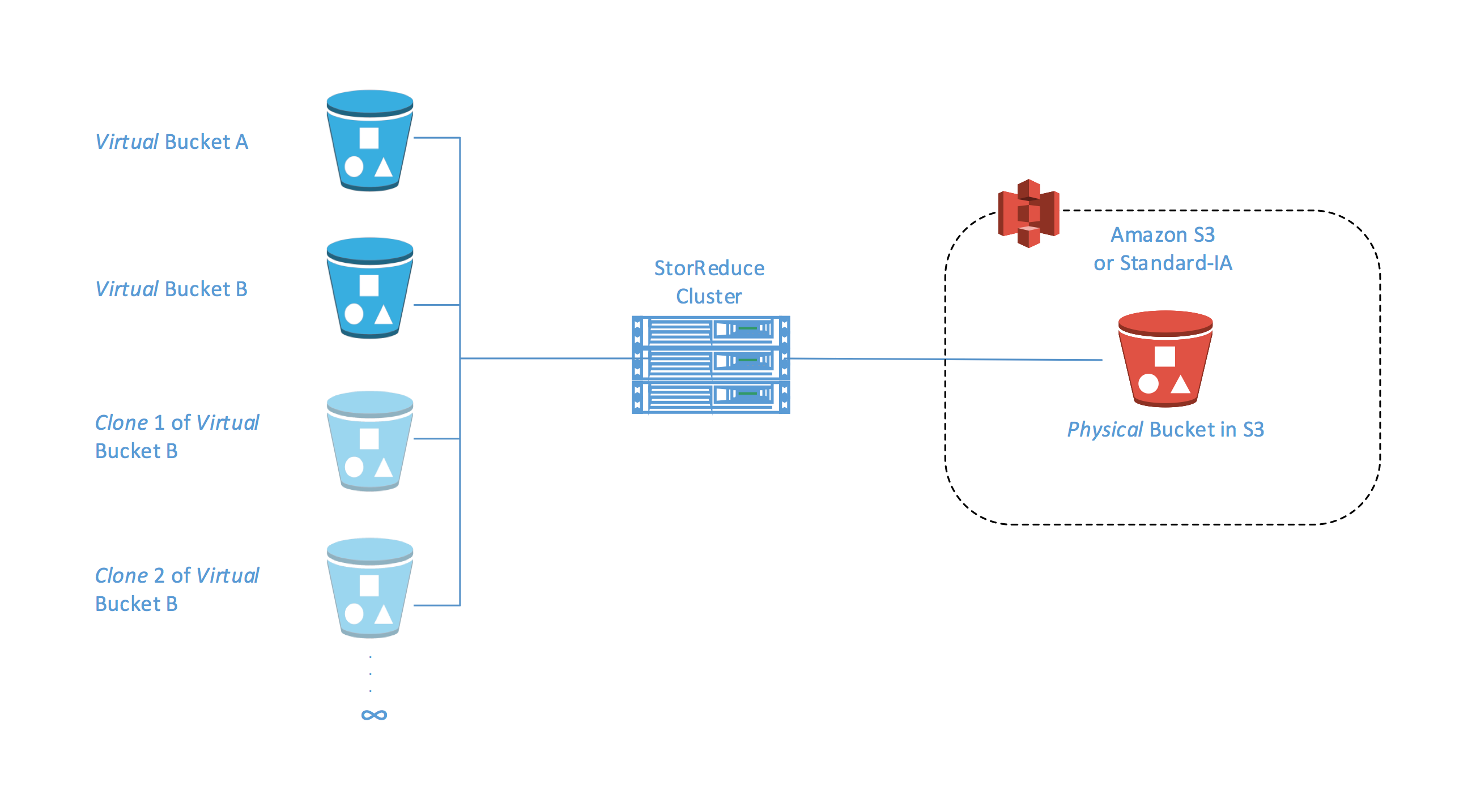
Today, we want to tell you about an innovative solution in this space from APN Technology Partner StorReduce that can help you do more with your data for less. StorReduce has announced support for cloning on object storage such as S3 and Standard-Infrequent Access (Standard – IA). This support allows users and administrators to make copy-on-write copies of objects stored with StorReduce in a rapid, space-efficient manner at petabyte scale.
Who is StorReduce?
StorReduce can help enterprises storing unstructured data to S3 or Amazon Glacier on AWS to reduce the amount and cost of storage significantly. It also offers enterprises another way to migrate backup appliance data and large tape archives to AWS.
StorReduce’s scale-out deduplication software runs on the cloud or in a data center and scales to petabytes of data. The variable block length deduplication removes any redundant blocks of data before it is stored so that only one copy of each block is stored. StorReduce provides throughput of more than 1 gigabyte per second per server for both reads and writes. A StorReduce cluster can scale to tens or hundreds of servers and provide throughputs of 10s to 100s of gigabytes per second. StorReduce is suitable to deduplicate most data workloads, particularly backup, archive, Hadoop cluster backups, and general unstructured file data. Because StorReduce has read-only endpoints and a cloud-native interface, data that it migrates to the AWS Cloud can be reused with cloud services.
Object storage cloning
Storage volume cloning is a long-standing feature of most on-premises NAS and SAN devices—a well-known example is NetApp FlexClone. In these environments, cloning enables fast snapshots of data, creating many additional copies of the data. Depending on the data change rate, deduplication can dramatically reduce the footprint of those extra copies, freeing up storage resources.
StorReduce’s Object Clone brings this feature to S3 and Standard – IA. Leveraging deduplication, a clone can be created simply by copying the references to the unique blocks that have been stored with StorReduce, while leaving the data stored in S3 unchanged.
Copying large amounts of object data may take hours per copy, and – lacking data reduction – you pay for every additional copy, regardless of how much of it is unique.
With StorReduce Object Clone, you need only copy a small amount of metadata. Copying petabyte-scale buckets becomes nearly instantaneous, and multiple clones can be created in rapid succession. Additionally, secondary and subsequent copies of the data are low cost, even at petabyte scale.
How StorReduce Object Clone works
Using the StorReduce dashboard to perform a “Clone Bucket” request is as easy as creating a bucket in StorReduce or S3. Simply navigate to the source bucket to clone. Choose Clone Bucket from the Actions dropdown and specify the target bucket name and StorReduce handles the rest. It creates a duplicate bucket that is owned by the initiator of the request, and which inherits the source bucket’s data.
Clones can also be created programmatically with two API calls, and you can always trace the name of the source bucket. If the source is deleted, this does not affect the operation, the contents of the clone, or access to it.
Benefits
StorReduce Object Clone provides a variety of benefits, including:
Increased flexibility – Provide cloud-based object storage with the same level of protection available to on-premises files or block data
Clone entire datasets at petabyte scale as many times as needed, quickly and affordably
Enable efficient, isolated application development and testing plus research and development against full datasets
Simplify the cloning of data in object stores, regardless of data deduplication ratios
Reduced management complexity – Administrators can quickly provide clones and reduce human error
Subsets of data can be made easily administrable for unbiased application testing
Protect against human error or malicious deletion of data in object stores
Make time-based clones of entire buckets and assign read-only access for “locking in” protected data at critical points in time
Reduced expense – Space-efficient clones consume less space and require less infrastructure
Enables you to meet your compliance requirements quickly where R&D or development activities require separate pools of data
Clone only small amounts of data in index or metadata, which reduces the clone size
Smaller clone size reduces cost of required infrastructure to store data for the second and subsequent copies, even at petabyte scale
Use cases
StorReduce Object Clone provides anyone who is working with a large dataset in S3 (whether that data deduplicates or not) the ability to try experiments and to fail and iterate quickly. Common use cases include:
Big data, Internet of Things, research – Clone petabyte-scale datasets so that researchers can work independently of each other in their own scratch areas.
IT operations – Test new versions of software against your dataset in isolation.
Developers, software testers – Clone your test datasets so that developers and testers can work with the whole dataset in insolation, not just a small subset. Roll the state back after failures and retest rapidly.
Software quality assurance – Take a lightweight clone of an entire system at the point that it fails a test and hand it back to the developer.
Hadoop, big data – Take point-in-time snapshots of the state of your cluster and roll back after problems.
To learn more about how AWS can help with your storage and backup needs, see the Storage and Backup details page.
This blog is not an endorsement of a third-party solution. It is intended for informational purposes.
What’s Next
If you like what you read here, the Cloud Brigade team offers expert Machine Learning as well as Big Data services to help your organization with its insights. We look forward to hearing from you.
Please reach out to us using our Contact Form with any questions.
If you would like to follow our work, please signup for our newsletter.
The company has just applied for a $150k grant through the Mission Main Street Grants program. We are competing with companies across the country for 20 grants provided by Chase bank in a partnership with Google. In order to qualify we need to get 250 votes by October 17th.
Why would a for-profit company need a grant?
As a company that subscribes to Triple Bottom Line methodologies, community is a big part of our corporate social mission, and with good reason.
In 2008 when I moved the company out of my home and into Santa Cruz, I had a really hard time growing beyond a one person company. Although we are just 30 miles away from Silicon Valley, absent were available workers with the skill set we needed for the services we provide.
The turning point came when we did a side project, a social experiment, in which we created a workforce training program. The idea was pretty simple; we offer a free comprehensive course in advanced software development, and exchange we simply ask that the rights to any code written be assigned back to us. We approached the local colleges, and somewhat surprisingly the program was well received by student interns from 18 to 58 who wanted training beyond what was available in our little beach community. We ran two semester long training sessions in 2010, and turned out 10 alumni.
Ultimately we had to terminate the program as we simply could not afford to fund it ourselves, and in a down economy there was no funding available despite interest and support from the City of Santa Cruz and Cabrillo College. The happy accident in this experiment was a good relationship with the Cabrillo College CS/CIS departments, and access to students who wanted to start a tech career in Santa Cruz. It was at that point internships became part of our company culture, in fact eight of our nine employees started as interns.
Now you might be asking yourself a lot of questions right now. Maybe the quality of the work we do is lower in quality or junior grade. Well you would be wrong. In fact I would argue that we are more detail oriented and quality conscious than many of our competitors, and I consider it a differentiator and just one way we stand out. I thank my father and the people who mentored me in my youth for teaching me the ethics and ideals that we teach our interns and employees.
You see, when you engage someone who is interested in learning and striving for their own personal excellence, which shines through in the work they do. When you get a group of likeminded people together in a team in an environment that supports cross pollination through sharing of knowledge, everyone is able to prosper on many levels.
OK, but what does all of this have to do with this grant? After growing the company responsibly over the last 9 years, 28 weeks, and 2 days, we are ready to take the company to the next level, with plans to double the size of the company in the next 1-2 years. As we experienced in the past, we are struggling to find the talent we need to grow the company. We’ve found plenty of great people, but the bridge between their current skill set and our job requirements is too large. Although we’ve continued to mentor locals through internships (over 30 in the last 4 years), we need to put people on the fast track to becoming employable.
Grant funding will enable us to create a comprehensive workforce training program with two technology tracks;
Linux Systems Administration
Responsive Website Development
What We Could Achieve
The funds will be used to create curriculum, lease space for a lab, pay instructors, and execute a 12-16 week class in each track for 6-10 students in the spring of 2015. If possible we will also run the session in the fall of 2015. We have been actively looking for other sources of funding for this program, and seek to sustain the program long after these funds will run out.
It is unlikely that we will be able to hire all of the alumni from the program, and that’s OK. Everyone who takes our courses will gain valuable experience which will enable them to gain employment from other area companies, much like the alumni from our original program from 2010, some of who work for us today. If this sounds like something you are willing to support, please vote for us so that we have a chance at obtaining grant funding to make this a reality.